A RAID array, also known as a redundant array of inexpensive (or independent) disks, is a group of hard drives that are arranged to store data together. While they might not be necessary for the casual computer user, RAID arrays play a key role in data centers big or small. RAID storage allows data centers to meet the demands of today’s storage needs through redundancy, performance, and of course huge storage capacities.

When things go wrong, however, they can go terribly wrong. Like a strand of Christmas lights with burnt-out bulbs, failed or offline drives can wreak havoc on a RAID. If two or more RAID disks go bad, in many cases that is enough to blink the entire storage system out of existence for users.
At that point, the network administrator managing the server has some difficult decisions to make, and likely with some urgency and pressure. One option that may seem attractive is to force an offline drive back online and thereby re-enable the entire RAID. This scenario is very common, and often results in a nice company share being run through the paper shredder as the RAID is rebuilt incorrectly.
Fortunately, Datarecovery.com has pioneered a method for cleanly recovering data from an incorrectly rebuilt RAID.
How an Incorrect RAID Rebuild Can Cause File System Issues
In order to understand Datarecovery.com’s process in this type of RAID recovery, it’s first important to understand exactly how RAID rebuilds work. To explain, let’s take a look at an example.
In a RAID-5 with three hard drives, the RAID can still function even if one of the three drives experiences an issue or fails completely. This RAID is said to be in a degraded state because it no longer has redundancy. Still, because it was previously redundant and the data from the two functional hard drives is still accessible, the RAID will continue to operate.
In the most common types of RAIDs (including this RAID-5 but also RAID-6, RAID-10, RAID-50), the RAID processor will write data “stripes” on each of the hard drives. A “stripe” is essentially just a chunk of data. The term demonstrates both that it isn’t writing complete data and that the data is spread across all the drives. In its simplest form, putting all of the stripes together forms a complete volume. (A volume is another word for a logical storage unit, such as the C: drive on a Windows computer.)
The RAID owner in our example can replace the one damaged hard drive and begin the process of rebuilding. Once the rebuild is finished, the RAID is redundant once more, and like last time, another hard drive failure would not result in any data loss. However, if the process was not done correctly or if hardware or software issues prevented a healthy rebuild, data loss can (and probably will) occur.
Common Issues That Can Result in a RAID Rebuild Failure
Additional Hard Drive Failures: If one component of the RAID fails and all the other disks are the same size and speed and operating in the same conditions, then those other RAID disks could be close to the end of their operating lives, too. Any one of those hard drives could fail next. In fact, running a rebuild will by its nature cause high mechanical stress that could then lead to an additional drive failure.
Other Hardware Issues: The RAID can become quite hot during the rebuild process, which can occasionally lead to a secondary failure. In addition to the heat, a sudden power failure could also prevent the RAID from successfully rebuilding. The surrounding hardware such as a RAID controller card, motherboard, or server backplane, may be the actual cause of the original drive going offline rather than the drive itself. In that situation, nothing stops it from occurring again and particularly during the high usage of a rebuild.
Accidental Rebuild Issues: In addition to these technological issues, there’s always a chance that you could make a mistake during the rebuild. For instance, you could accidentally run a rebuild with hard drives in an improper order or configuration.
Rebuild attempts with the above conditions will have unpredictable consequences. The rebuild could stop immediately, or the entire RAID could be overwritten, effectively wiping all the data.
How Datarecovery.com Achieved a Full, Clean Recovery From a RAID-5 with Six Hard Drives
The Scenario: Datarecovery.com was contacted by the network administrator of a RAID server system who had suddenly lost power due to an outage. According to the network administrator, the data appeared to be damaged when the power came back and the array finally restarted. The client could not determine whether there had been an attempted rebuild, but one thing was clear: due to the importance of the data, a full recovery was the top priority.
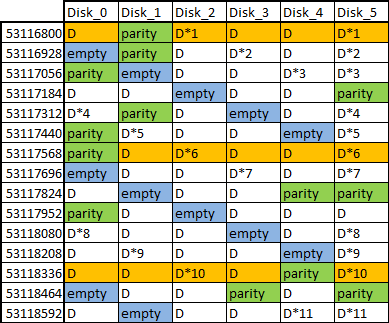
The Analysis: Upon receiving the RAID and examining what went wrong, a Datarecovery.com engineer discovered scattered data, almost like it had gone through a virtual paper shredder. This was a clear indication of a failed rebuild. However, there was no recognizable method to the madness beyond an empty block in five out of every six stripes. (A block is one part of a stripe of data.) Additionally, on most of the stripes, the data block on the last drive was identical with the data block on another block within the stripe. This implied that a manual rebuild had been attempted, but wasn’t successful.
After tracing the sequential data and taking note of the order of the data blocks, Datarecovery.com’s engineers were able to figure out that some blocks were missing. However, from stripe to stripe, data appeared to progress correctly. Engineers determined that this meant the RAID had previously been rebuilt with an additional drive added to the array. What now appeared to be a six-drive RAID-5 with serious problems was originally a five-drive RAID-5.
The Process: After figuring out the root cause of the issue, Datarecovery.com’s first goal was to tackle the missing data blocks. Some stripes had no empty blocks, and other stripes had a duplicated block in place of a parity block (redundancy data), so those stripes were excluded from this part. But for the remaining bulk of stripes, engineers performed “spot tests” and were successful in hand-rebuilding the empty blocks.
Here, engineers were faced with the huge amount of data and the extremely unusual block pattern. They needed an automated solution that didn’t currently exist so they could perform a similar calculation over the full lengths of all the hard drives. They turned to Datarecovery.com’s programming specialist who developed a program that identified the empty blocks using the consistent pattern in figure 1, rebuilt missing blocks using the right combination of the existing good data blocks and the parity block, and then wrote it to a logical copy of the drive images.
After running the program, the engineering team analyzed the RAID array again. The missing data blocks had been recreated, and they could see there was no longer missing data within the stripes. However there was still a major problem — the erratic block order.
Because the fifth drive only contained repeat data and Datarecovery.com engineers had already used it to successfully recalculate the missing blocks, the engineers were able to ignore that drive for the rest of the process. This now presented the team with a 5-drive RAID-5 with an unusual block order.
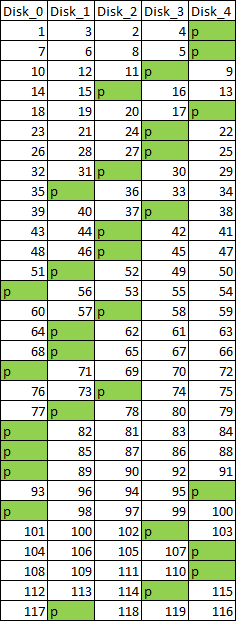
To create a usable system, Datarecovery.com engineers needed to reorder the blocks. But there was no easily discernible pattern to the data blocks. Off-the-shelf software tools certainly were no help at this point. Because there were over two million data blocks within this RAID, manually reconstructing the blocks was not an option. Datarecovery.com engineers would need to determine a pattern (if one existed) in order to reconstruct.
To do this, engineers mapped a large number of blocks in hopes of discovering a repeating pattern. Initially mapping only the parity blocks, repetition was finally found in a 30-stripe pattern after 60 stripes had been mapped. Engineers made “spot checks” to other locations to confirm the pattern. Then the engineers performed the longer process of mapping the order of the four data blocks in each of those stripes. When that was done, engineers had defined the complete block order pattern shown in figure 2.
Datarecovery.com’s engineers then built a template of the RAID’s block order compatible with more conventional RAID software tools. These tools are commonly used to process standard RAID patterns. But in this case, the template allowed the software to follow the unique pattern of this array in order to successfully rebuild the RAID and place all the data blocks into the correct sequential order.
The Result: Datarecovery.com was able to successfully achieve a positive result with no corruption whatsoever — all files across the RAID-5 were finally accessible. Despite the incorrect rebuild and seemingly insurmountable data order issues, Datarecovery.com was able to provide a complete copy of all files on the array.
It’s Still Possible to Recover Data From an Incorrectly Rebuilt RAID Array
To put it simply, an incorrect RAID rebuild can cause more damage to your data than you realize, and the risk of this loss is too great to just leave up to chance. For this reason, it’s always best to pursue professional RAID data recovery services instead of trying to figure things out yourself. If you’re dealing with issues with your RAID, don’t hesitate to contact the professionals at Datarecovery.com and seek their help. Datarecovery.com’s expert engineers have proven time and time again that RAID recovery is possible, even if the RAID has been incorrectly rebuilt. Contact Datarecovery.com today for a free quote.